2026年MySQL最新面试题 - MySQL事务
# 0、概要
- 什么是数据库事务?
- 事物的四大特性(ACID)介绍一下?
- 什么是脏读?幻读?不可重复读?
- 什么是事务的隔离级别?MySQL的默认隔离级别是什么?
- 隔离级别的实现原理
- 事务延伸点: 分布式事务
# 1、 什么是数据库事务?
出现概率: ★★★★★
简单来说:数据库事务可以保证多个对数据库的操作(也就是 SQL 语句)构成一个逻辑上的整体。构成这个逻辑上的整体的这些数据库操作遵循:要么全部执行成功,要么全部不执行 。
# 开启一个事务
START TRANSACTION;
# 多条 SQL 语句
SQL1,SQL2...
## 提交事务
COMMIT;
事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红转账 1000 元,这个转账会涉及到两个关键操作就是:
将小明的余额减少 1000 元 将小红的余额增加 1000 元。 事务会把这两个操作就可以看成逻辑上的一个整体,这个整体包含的操作要么都成功,要么都要失败。
这样就不会出现小明余额减少而小红的余额却并没有增加的情况。
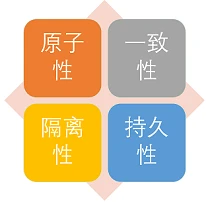
# 2、事物的四大特性(ACID)介绍一下?
出现概率: ★★★★
ACID,指数据库事务正确执行的四个基本要素的缩写。包含:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。一个支持事务(Transaction)的数据库,必需要具有这四种特性,否则在事务过程(Transaction processing)当中无法保证数据的正确性,交易过程极可能达不到交易方的要求。
# 3、什么是脏读?幻读?不可重复读?
出现概率: ★★★★
1、脏读
脏读是指在一个事务处理过程里读取了另一个未提交的事务中的数据。
当一个事务正在多次修改某个数据,而在这个事务中这多次的修改都还未提交,这时一个并发的事务来访问该数据,就会造成两个事务得到的数据不一致。例如:用户A向用户B转账100元,对应SQL命令如下
update account set money=money+100 where name=’B’; (此时A通知B)
update account set money=money - 100 where name=’A’;
当只执行第一条SQL时,A通知B查看账户,B发现确实钱已到账(此时即发生了脏读),而之后无论第二条SQL是否执行,只要该事务不提交,则所有操作都将回滚,那么当B以后再次查看账户时就会发现钱其实并没有转。
2、不可重复读 不可重复读是指在对于数据库中的某个数据,一个事务范围内多次查询却返回了不同的数据值,这是由于在查询间隔,被另一个事务修改并提交了。 例如事务T1在读取某一数据,而事务T2立马修改了这个数据并且提交事务给数据库,事务T1再次读取该数据就得到了不同的结果,发生了不可重复读。
不可重复读和脏读的区别是,脏读是某一事务读取了另一个事务未提交的脏数据,而不可重复读则是读取了前一事务提交的数据。 在某些情况下,不可重复读并不是问题,比如我们多次查询某个数据当然以最后查询得到的结果为主。但在另一些情况下就有可能发生问题,例如对于同一个数据A和B依次查询就可能不同,A和B就可能打起来了……
3、虚读(幻读)
幻读是事务非独立执行时发生的一种现象。例如事务T1对一个表中所有的行的某个数据项做了从“1”修改为“2”的操作,这时事务T2又对这个表中插入了一行数据项,而这个数据项的数值还是为“1”并且提交给数据库。而操作事务T1的用户如果再查看刚刚修改的数据,会发现还有一行没有修改,其实这行是从事务T2中添加的,就好像产生幻觉一样,这就是发生了幻读。
幻读和不可重复读都是读取了另一条已经提交的事务(这点就脏读不同),所不同的是不可重复读查询的都是同一个数据项,而幻读针对的是一批数据整体(比如数据的个数)。
SQL标准定义了4类隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的。低级别的隔离级一般支持更高的并发处理,并拥有更低的系统开销。
# 4、什么是事务的隔离级别?MySQL的默认隔离级别是什么?
出现概率: ★★★★
MySQL的事务隔离级别一共有四个,分别是读未提交、读已提交、可重复读以及可串行化。
MySQL的隔离级别的作用就是让事务之间互相隔离,互不影响,这样可以保证事务的一致性。
隔离级别比较:可串行化>可重复读>读已提交>读未提交
隔离级别对性能的影响比较:可串行化>可重复读>读已提交>读未提交
由此看出,隔离级别越高,所需要消耗的MySQL性能越大(如事务并发严重性),为了平衡二者,一般建议设置的隔离级别为可重复读,MySQL默认的隔离级别也是可重复读。
# 5、隔离级别的实现原理
出现概率: ★★★
这里使用MySQL的默认隔离级别(可重复读)来进行说明 隔离级别的实现原理。
每条记录在更新的时候都会同时记录一条回滚操作(回滚操作日志undo log)。同一条记录在系统中可以存在多个版本,这就是数据库的多版本并发控制(MVCC)。即通过回滚(rollback操作),可以回到前一个状态的值。
假设一个值从 1 被按顺序改成了 2、3、4,在回滚日志里面就会有类似下面的记录。
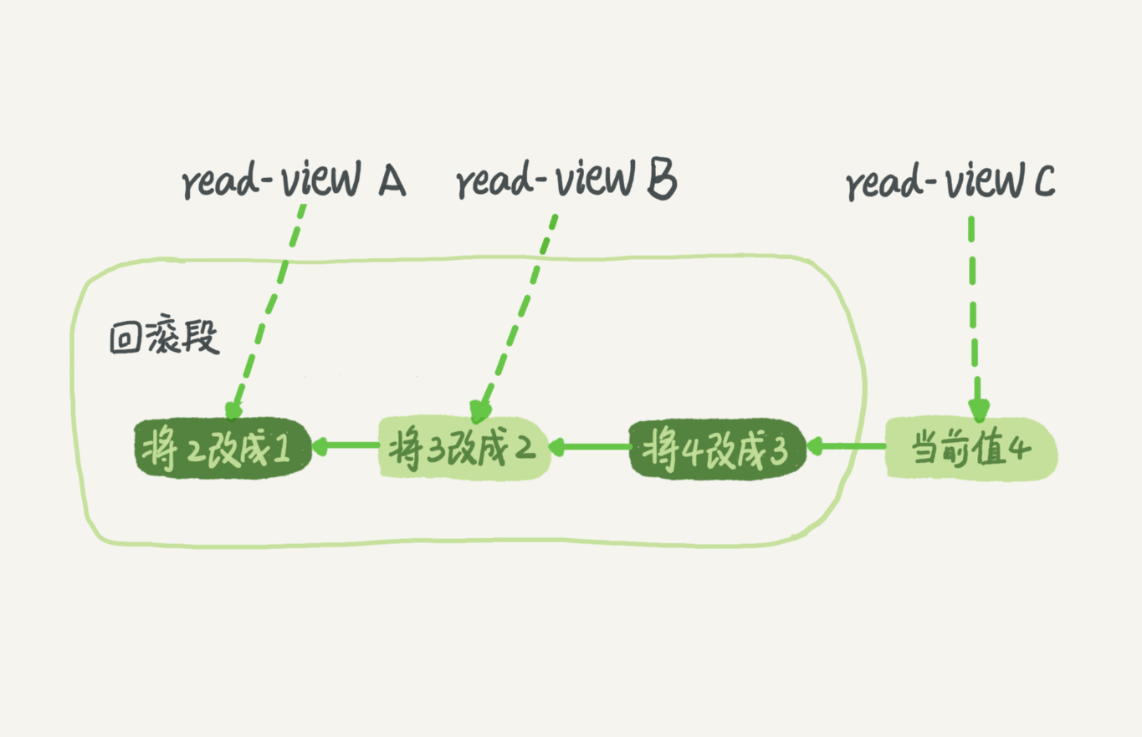
当前值是 4,但是在查询这条记录的时候,不同时刻启动的事务会有不同的 read-view。如图中看到的,在视图 A、B、C 里面,这一个记录的值分别是 1、2、4,同一条记录在系统中可以存在多个版本,就是数据库的多版本并发控制(MVCC)。对于 read-view A,要得到 1,就必须将当前值依次执行图中所有的回滚操作得到。
同时你会发现,即使现在有另外一个事务正在将 4 改成 5,这个事务跟 read-view A、B、C 对应的事务是不会冲突的。
提问:回滚操作日志(undo log)什么时候删除?
MySQL会判断当没有事务需要用到这些回滚日志的时候,回滚日志会被删除。
提问:什么时候不需要了?
当系统里么有比这个回滚日志更早的read-view的时候。
# 6、 事务延伸点: 什么是分布式事务, 有哪些解决方案?
出现概率: ★★★
这个主要看面试官的喜好, 如果用的是微服务架构,平时开发中会遇到蛮多案例的,不过相信很多人没有思考过这个的解决方案。
这里介绍一个分布式事务典型场景: 银行跨行转账业务是一个典型分布式事务场景,假设A需要跨行转账给B,那么就涉及两个银行的数据,无法通过一个数据库的本地事务保证转账的正确性,只能够通过分布式事务来解决。
将服务拆分为微服务时,遇见类似需要分布式事务的场景非常多,虽然微服务最佳实践建议尽量规避分布式事务,但是在很多业务场景,分布式事务是一个绕不开的技术问题。
分布式事务模式常见的有XA、TCC、SAGA、可靠消息。
1)、两阶段提交/XA
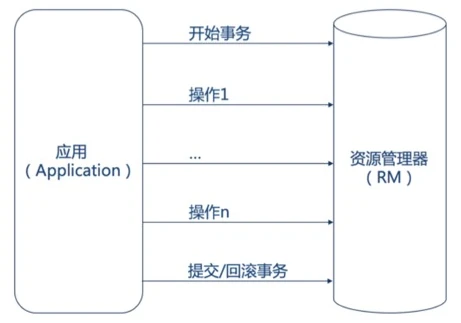
XA是由X/Open组织提出的分布式事务的规范,XA规范主要定义了(全局)事务管理器(TM)和(局部)资源管理器(RM)之间的接口。本地的数据库如mysql在XA中扮演的是RM角色
XA一共分为两阶段:
第一阶段(prepare):即所有的参与者RM准备执行事务并锁住需要的资源。参与者ready时,向TM报告已准备就绪。
第二阶段 (commit/rollback):当事务管理者(TM)确认所有参与者(RM)都ready后,向所有参与者发送commit命令。
目前主流的数据库基本都支持XA事务,包括mysql、oracle、sqlserver、postgre
2)、TCC事务方案
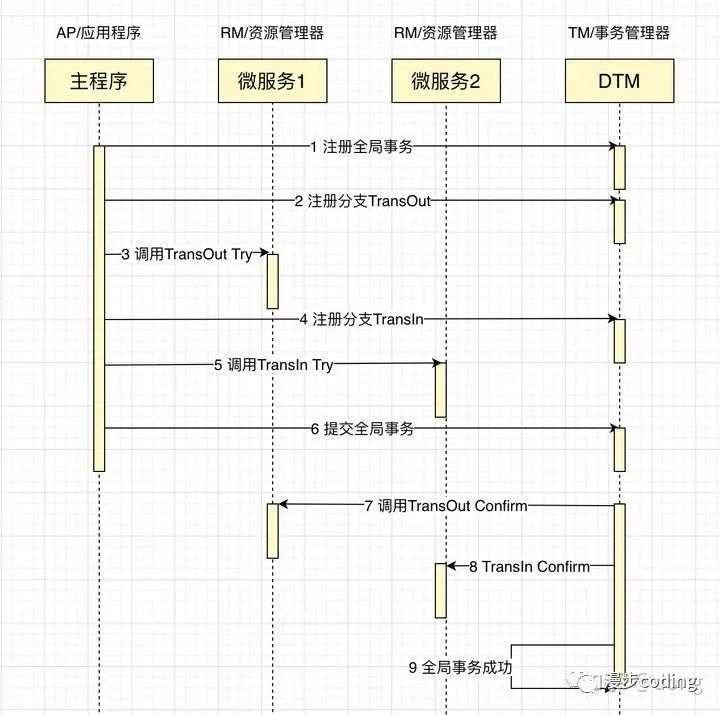
TCC方案其实是XA提交的一种改进。其将整个业务逻辑的每个分支显式的分成了Try、Confirm、Cancel三个操作。Try部分完成业务的准备工作,confirm部分完成业务的提交,cancel部分完成事务的回滚。
3)、SAGA事务方案
Saga和TCC一样,也是最终一致性事务、柔性事务。Saga的本质就是把一个长事务分隔成一个个小的事务,每个事务都包含一个执行模块和补偿模块。 Saga没有try,直接提交事务,可能出现脏读的情况,在某些对一致性要求较高的场景下,是不可接受的。
在启动一个Saga事务时,事务管理器会告诉第一个Saga参与者,也就是子事务,去执行本地事务。事务完成之后Saga的会按照执行顺序调用Saga的下一个参与的子事务。这个过程会一直持续到Saga事务执行完毕。
如果在执行子事务的过程中遇到子事务对应的本地事务失败,则Saga会按照相反的顺序执行补偿事务。
4)、可靠消息
消息一致性方案是通过消息中间件保证上下游应用数据操作的一致性。基本思路是将本地操作和发送消息放在一个本地事务中,保证本地操作和消息发送要么两者都成功或者都失败。下游应用向消息系统订阅该消息,收到消息后执行相应操作。
RocketMQ 提供了典型的可靠消息接口,可以参考
也欢迎关注我的公众号: 漫步coding, 回复: mysql免费获取最新Mysql面试题汇总(含答案)。 一起交流, 在coding的世界里漫步。

希望这篇文章可以帮助大家, 也希望大家都能找到找到的好工作。