2026年MySQL最新面试题 - MySQL存储引擎
# 三、存储引擎
# 0、概要
- 1、可以简单谈谈MySQL存储引擎MyISAM与InnoDB区别
- 2、MyISAM索引与InnoDB索引的区别?
- 3、InnoDB引擎的4大特性
# 1、可以简单谈谈MySQL存储引擎MyISAM与InnoDB区别
出现概率: ★★★★
1)、关于 InnoDB
InnoDB 是 MySQL 的默认事务型引擎,用来处理大量短期事务。InnoDB 的性能和自动崩溃恢复特性使得它在非事务型存储需求中也很流行,除非有特别原因否则应该优先考虑 InnoDB。
InnoDB 的数据存储在表空间中,表空间由一系列数据文件组成。MySQL4.1 后 InnoDB 可以将每个表的数据和索引放在单独的文件中。
InnoDB 采用 MVCC 来支持高并发,并且实现了四个标准的隔离级别。其默认级别是 REPEATABLE READ,并通过间隙锁策略防止幻读,间隙锁使 InnoDB 不仅仅锁定查询涉及的行,还会对索引中的间隙进行锁定防止幻行的插入。
InnoDB 表是基于聚簇索引建立的,InnoDB 的索引结构和其他存储引擎有很大不同,聚簇索引对主键查询有很高的性能,不过它的二级索引中必须包含主键列,所以如果主键很大的话其他所有索引都会很大,因此如果表上索引较多的话主键应当尽可能小。
InnoDB 的存储格式是平立的,可以将数据和索引文件从一个平台复制到另一个平台。
InnoDB 内部做了很多优化,包括从磁盘读取数据时采用的可预测性预读,能够自动在内存中创建加速读操作的自适应哈希索引,以及能够加速插入操作的插入缓冲区等。
2)、关于MyISAM
MySQL5.1及之前,MyISAM 是默认存储引擎,MyISAM 提供了大量的特性,包括全文索引、压缩、空间函数等,但不支持事务和行锁,最大的缺陷就是崩溃后无法安全恢复。对于只读的数据或者表比较小、可以忍受修复操作的情况仍然可以使用 MyISAM。
MyISAM 将表存储在数据文件和索引文件中,分别以 .MYD 和 .MYI 作为扩展名。MyISAM 表可以包含动态或者静态行,MySQL 会根据表的定义决定行格式。MyISAM 表可以存储的行记录数一般受限于可用磁盘空间或者操作系统中单个文件的最大尺寸。
MyISAM 对整张表进行加锁,读取时会对需要读到的所有表加共享锁,写入时则对表加排它锁。但是在表有读取查询的同时,也支持并发往表中插入新的记录。
对于MyISAM 表,MySQL 可以手动或自动执行检查和修复操作,这里的修复和事务恢复以及崩溃恢复的概念不同。执行表的修复可能导致一些数据丢失,而且修复操作很慢。
对于 MyISAM 表,即使是 BLOB 和 TEXT 等长字段,也可以基于其前 500 个字符创建索引。MyISAM 也支持全文索引,这是一种基于分词创建的索引,可以支持复杂的查询。
MyISAM 设计简单,数据以紧密格式存储,所以在某些场景下性能很好。MyISAM 最典型的性能问题还是表锁问题,如果所有的查询长期处于 Locked 状态,那么原因毫无疑问就是表锁。
# 2、MyISAM索引与InnoDB索引的区别?
出现概率: ★★★★
MyISM和InnoDB索引都是由B+树实现的,但在索引管理数据方式上却有所不同。
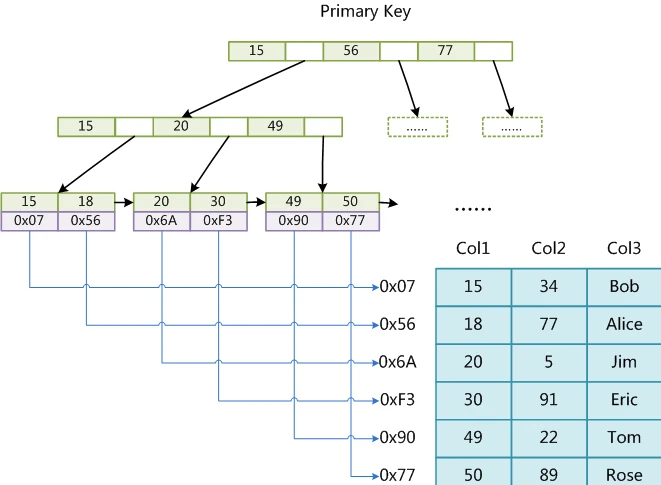
1)、InnoDB是聚集索引,数据文件是和(主键)索引绑在一起的,即索引 + 数据 = 整个表数据文件,通过主键索引到整个记录,必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,因为辅助索引是以建索引的字段为关键字索引到主键,所以需要两次,先查询到主键,然后再通过主键查询到数据。
主键索引:以主键索引到整条记录
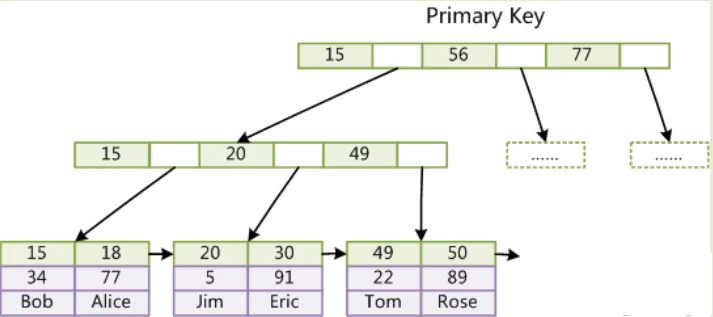
辅助索引:以另一字段索引到主键
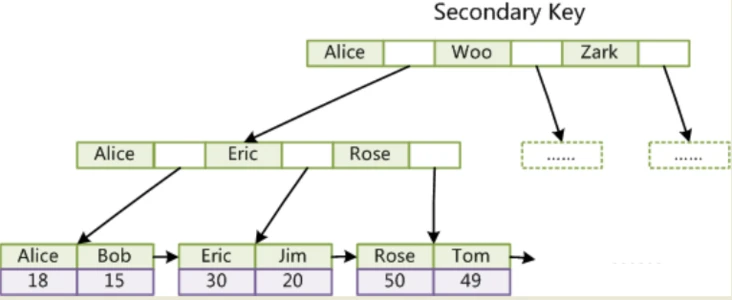
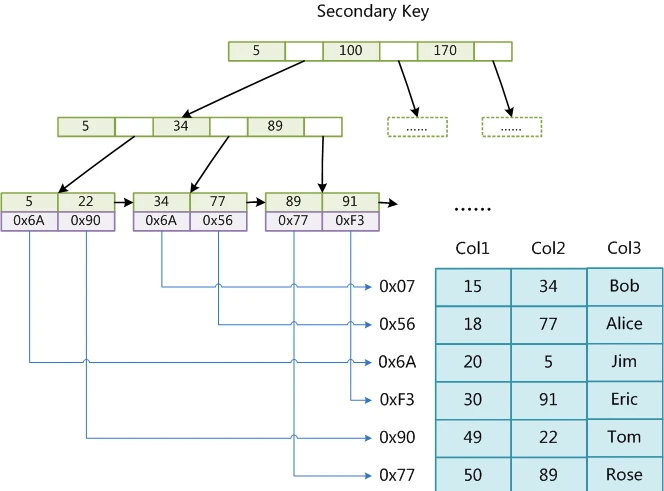
2)、MyISAM是非聚集索引,也是使用B+Tree作为索引结构,索引和数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。也就是说:InnoDB的B+树主键索引的叶子节点就是数据文件,辅助索引的叶子节点是主键的值;而MyISAM的B+树主键索引和辅助索引的叶子节点都是数据文件的地址指针。
主键索引:以关键字索引到记录的地址
辅助索引:以某字段索引到记录地址
# 3、InnoDB引擎的4大特性
出现概率: ★★★
1)、插入缓冲 (Insert Buffer/Change Buffer)
插入缓存之前版本叫insert buffer,现版本 change buffer,主要提升插入性能,change buffer是insert buffer的加强,insert buffer只针对insert有效,change buffering对insert、delete、update(delete+insert)、purge都有效。
2)、双写机制(Double Write)
在InnoDB将BP中的Dirty Page刷(flush)到磁盘上时,首先会将(memcpy函数)Page刷到InnoDB tablespace的一个区域中,我们称该区域为Double write Buffer(大小为2MB,每次写入1MB,128个页,每个页16k,其中120个页为后台线程的批量刷Dirty Page,还有8个也是为了前台起的sigle Page Flash线程,用户可以主动请求,并且能迅速的提供空余的空间)。在向Double write Buffer写入成功后,第二步、再将数据分别刷到一个共享空间和真正应该存在的位置。
3)、自适应哈希索引(Adaptive Hash Index,AHI)
哈希算法是一种非常快的查找方法,在一般情况(没有发生hash冲突)下这种查找的时间复杂度为O(1)。InnoDB存储引擎会监控对表上辅助索引页的查询。如果观察到建立hash索引可以提升性能,就会在缓冲池建立hash索引,称之为自适应哈希索引(Adaptive Hash Index,AHI)。
4)、预读 (Read Ahead)
预读(read-ahead)操作是一种IO操作,用于异步将磁盘的页读取到buffer pool中,预料这些页会马上被读取到。预读请求的所有页集中在一个范围内。
也欢迎关注我的公众号: 漫步coding, 回复: mysql免费获取最新Mysql面试题汇总(含答案)。 一起交流, 在coding的世界里漫步。

希望这篇文章可以帮助大家, 也希望大家都能找到找到的好工作。