2026年MySQL最新面试题 - MySQL部署和运维
# 0、概要
- 1、如何更新给一个大表建索引
- 2、如何批量删除N行记录, 有什么注意事项
- 3、如何删除表?
- 4、MySQL如何扩容
- 5、如何排查因为MySQL导致CPU占用高的问题?
- 6、MySQL数据库磁盘IO使用高,请问如何进行排查?
- 7、如何批量插入大量数据?
- 8、数据备份和恢复
# 1、如何更新给一个大表建索引
出现概率: ★★★★
这个问题考察的点: 线上高并发下的添加大表建索引
当表数据量很大时,建立索引或者修改表结构会很慢,而且在操作的过程中,数据库甚至处于死锁状态,那么有没有其他的好的办法呢?
方式1、“影子策略”
- 创建一张与原表(tb)结构相同的新表(tb_new)
- 在新表上创建索引
- 重命名原表为其他表名(tb => tb_tmp),新表重命名为原表名(tb_new => tb),此时新表(tb)承担业务
- 为原表(tb_tmp)新增索引
- 交换表,新表改回最初的名称(tb => tb_new),原表改回最初的名称(tb_tmp => tb),原表(tb)重新承担业务
- 把新表数据导入原表(即把新表承担业务期间产生的数据和到原表中)
# 以下sql对应上面六步
create table tb_new like tb;
alter table tb_new add index idx_col_name (col_name);
rename table tb to tb_tmp, tb_new to tb;
alter table tb_tmp add index idx_col_name (col_name);
rename table tb to tb_new, tb_tmp => tb;
insert into tb (col_name1, col_name2) select col_name1, col_name2 from tb_new;
在生产环境, 这个方式有比较严重的问题, 步骤3之后,新表改为原表名后(tb)开始承担业务,步骤3到结束之前这段时间的新产生的数据都是存在新表中的,但是如果有业务对老数据进行修改或删除操作,那将无法实现,所以步骤3到结束这段时间可能会产生数据(更新和删除)丢失。
方式2、利用辅助工具 Percona Toolkit 是一组高级的命令行工具,用来管理 MySQL 和系统任务,主要包括:
- 验证主节点和复制数据的一致性
- 有效的对记录行进行归档
- 找出重复的索引
- 总结 MySQL 服务器
- 从日志和 tcpdump 中分析查询
- 问题发生时收集重要的系统信息
- 在线修改表结构
工作原理如下:
- 如果存在外键,根据 alter-foreign-keys-method 参数的值,检测外键相关的表,做相应设置的处理。没有使用 alter-foreign-keys-method 指定特定的值,该工具不予执行
- 创建一个新的空表,其命名规则是:下划线 + 原表名 +_new—-_原表名_new
- 根据 alter 语句,更新新表的表结构;
- 创建触发器,用于记录从拷贝数据开始之后,对源数据表继续进行数据修改的操作记录下来,用于数据拷贝结束后,执行这些操作,保证数据不会丢失。如果表中已经定义了触发器这个工具就不能工作了。
- 拷贝数据,从源数据表中拷贝数据到新表中。
- 修改外键相关的子表,根据修改后的数据,修改外键关联的子表。
- rename 源数据表为 old 表,把新表 rename 为源表名,其通过一个 RENAME TABLE 同时处理两个表,实现原子操作。(RENAME TABLE dbteamdb.user TO dbteamdb._user_old, dbteamdb._user_new TO dbteamdb.user)
- 将 old 表删除、删除触发器。
方式3、凌晨进行维护, 添加索引, 一部分公司也是这么做的, 但是不够灵活,遇到一些紧急情况还是方式2更好些。
# 2、 如何批量删除N行记录, 有什么注意事项
出现概率: ★★★★
因为批量删除大表大量数据时, 数据会锁表, 在业务高峰时会导致 数据库CPU暴涨, 降低服务器性能, 可能会造成数据库雪崩现象。
这个也是每个线上开发人员可能遇到的业务场景。
方式1、删除大表的多行数据时,会超出innod block table size的限制,最小化的减少锁表的时间的方案是:
- 选择不需要删除的数据,并把它们存在一张相同结构的空表里
- 重命名原始表,并给新表命名为原始表的原始表名
- 删掉原始表
这个会有一个问题, 正式环境删除间隙的数据同步问题。
方式2、将批量删除任务拆减成 N个小删除任务, 比如只删1w条后, 将删除任务压入到异步队列等待执行.
方式3、删除表上的索引, 在删除数据, 可以提高效率, 但是不太适合线上环境.
# 3、如何删除表
出现概率: ★★★★
这个是如何批量删除N行记录的延伸问题.
如果我们清空表数据,建议直接使用truncate,效率上truncate远高于delete,在另一篇文章讲mysql的,可以得知,我们truncate不走事务,不会锁表,也不会产生大量日志写入日志文件,我们访问log执行日志可以发现每次delete都有记录。truncate table table_name 会立刻释放磁盘空间,并重置auto_increment的值,delete 删除不释放磁盘空间,insert会覆盖之前的数据上,因为我们创建表的时候有一个创建版本号。
# 4、MySQL如何扩容
出现概率: ★★★
目前可用方案
1)、MySQL的复制:
一个Master数据库,多个Salve,然后利用MySQL的异步复制能力实现读写分离,这个方案目前应用比较广泛,这种技术对于以读为主的应用很有效。 数据切分(MySQL的Sharding策略):
- 垂直切分:一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)之上,这种切可以称之为数据的垂直(纵向)切分;垂直切分的思路就是分析表间的聚合关系,把关系紧密的表放在一起。
- 水平切分:另外一种则是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种切分称之为数据的水平(横向)切分。
2)、通过集群扩展:MySQL Cluster(NDB Cluster)
类似于MongoDB的动态扩容策略。
MySQL Cluster是一套具备可扩展能力、实时、内存内且符合ACID要求的事务型数据库,其将99.999%高可用性与低廉的开源总体拥有成本相结合。在设计思路方面,MySQL Cluster采用一套分布式多主架构并借此彻底消灭了单点故障问题。MySQL Cluster能够横向扩展至商用硬件之上,能够通过自动分区以承载读取与写入敏感型工作负载,并可通过SQL与NoSQL接口实现访问。
采用NDB存储引擎,有数据节点,SQL节点,和管理节点(1个,配置要求低)
3)、分库分表分区
# 5、如何排查因为MySQL导致CPU占用高的问题?
出现概率: ★★★
在问题出现之前, 我们需要做的是加强监控, 比如当CPU暴涨到85%时就进行报警, 这样当有问题时, 开发人员和运维人员可以第一时间收到报警, 并处理, 而不是让用户报出来: 你家APP是不是又崩了, 卡死了。
我们平时遇到大部分MySQL导致CPU占用高的情况是因为慢查询实例出现CPU飙升。这种情况表现是QPS(每秒执行的查询次数)不高;查询执行效率低、执行时需要扫描大量表中数据。此时可能是由于存在慢查询导致,查询执行效率低,为了获取预期的结果就需要访问大量的数据,导致平均逻辑IO增高,此时就会是CPU利用率过高。
此时需要DBA,定位效率低的查询、优化查询的执行效率、降低查询执行的成本。
具体定位的过程可以参考:
1)、通过在控制台下载慢查询日志,定位效率低的SQL并进行优化
2)、也可以通过 show processlist; 或 show full processlist; 命令查看当前执行的查询,反复执行,找到慢查询的process ID ,运行kill 慢查询的id 命名杀掉慢查询进程。
同时MySQL处在高负载环境下,磁盘IO读写过多,也会占用很多资源,必然会使CPU占用过高。CPU过高,可以从下面几个方向进行排查问题和优化:
1)、打开慢查询日志,查询是否是某个SQL语句占用过多资源,如果是的话,可以对SQL语句进行优化,比如优化 insert 语句、优化 group by 语句、优化 order by 语句、优化 join 语句等等;
2)、考虑索引问题;
3)、定期分析表,使optimize table;
4)、优化数据库对象;
5)、考虑是否是锁问题;
6)、调整一些MySQL Server参数,比如key_buffer_size、table_cache、innodb_buffer_pool_size、innodb_log_file_size等等;
7)、如果数据量过大,可以考虑使用MySQL集群或者搭建高可用环境。
8)、考虑磁盘是否满了
# 6、MySQL数据库磁盘IO使用高,请问如何进行排查?
出现概率: ★★★
我们以mysql5.7版本为例,结合performance_schema来查看MySQL数据库的各种指标。IO的话,可以查看这张表:
performance_schema.file_instances:列出了文件I O操作及其相关文件的工具实例
一般遇到问题时的排查思路:
1、慢SQL排除
2、硬件问题-RAID降级,磁盘故障等排除
3、innodb_log、innodb_buffer_pool_wait相关配置
4、IO相关参数配置
innodb_flush_method = O_DIRECT
innodb_file_per_table = 1
innodb_doublewrite = 1
delay_key_write
innodb_read_io_threads
innodb_read_io_threads
innodb_io_capacity
innodb_flush_neighbors
sync_binlog
其中可以主要关注:sync_binlog, binlog刷新的参数,默认是1。
mysql> show variables like '%sync_bin%';
+--------------+-------+
| Variable_name | Value |
+---------------+-------+
| sync_binlog | 1 |
+---------------+-------+
1 row in set (0.00 sec)
sync_binlog为1, 表示每次事务提交后MySQL将进行一次fsync之类的磁盘同步指令来将binlog_cache中的数据强制写入磁盘,频繁的写盘导致磁盘IO居高不下,将sync_binlog调整为500。
大家都知道,影响数据库最大的性能问题就是磁盘IO,为了提升数据库的IOPS,可以使用SSD或者PCIE-SSD高速磁盘。内存方面也很重要,内存可以缓存热点数据和存储引擎文件,避免产生过多的物理IO,可以增加物理内存来提高数据库的并发和读写性能。
最后也建议:最好部署相关的监控平台或者对比历史性能记录,结合业务以及负载来分析。
# 7、如何批量插入大量数据?
出现概率: ★★★
1)、自己也循环一条一条插入, 缺点时因为频繁建立连接, 比较耗时
2)、减少连接资源,拼接一条sql,这样写一次正常插入一万条基本问题不大,除非数据很长,应付普通的批量插入够用了,比如:批量生成卡号,批量生成随机码等等。
3)、使用存储过程
delimiter $$$
create procedure zqtest()
begin
declare i int default 0;
set i=0;
start transaction;
while i<80000 do
//your insert sql
set i=i+1;
end while;
commit;
end
$$$
delimiter;
call zqtest();
4)、使用MYSQL LOCAL_INFILE
LOAD DATA LOCAL INFILE 'F:\\milo.csv' INTO TABLE test
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\r\n'
IGNORE 1 LINES
(id, name)
时间对比:
经过测试插入1w条数据时候与拼装批量插入语句时间差别不大,当插入数量达到10w出现了明显的时间差:
拼装批量插入语句花费时间:6.83s
LOAD DATA LOCAL INFILE实现大批量插入花费时间:1.23s
当表格的字段更多数据量更大出现的时间差就越大。
总结:当需要进行大批量数据插入的时候,可以优先考虑LOAD DATA LOCAL INFILE实现方式。
# 8、数据备份和恢复
出现概率: ★★★★
Mysql 提供了 mysqldump、ibbackup、replication 工具来备份, 关于备份需要了解的几个概念:
1)、数据备份按备份类型:
- 热备:在数据库运行过程中直接备份, 读写操作均可执行
- 冷备:在数据库停止的情况下备份,读写操作均不可进行,一般直接复制相关的物理文件即可
- 温备:在数据库运行过程中备份, 读操作可执行;但写操作不可执行,但对数据库操作有影响,如加个全局读锁以保证备份数据一致性
关于热备原理:
双机热备就是使用MySQL提供的一种主从备份机制实现。所谓双机热备其实是一个复制的过程,复制过程中一个服务器充当主服务器,一个或多个服务器充当从服务。这个复制的过程实质上是从服务器复制主服务器上MySQL的二进制日志(bin-log),并在从服务器上还原主服务器上的sql语句操作,这样只要两个数据库的初态是一样的,就能一直同步。
双机热备的实现需要MySQL的版本高于3.2.。另外由于这种备份是基于MySQL二进制日志实现,所以主从服务器上的MySQL版本最好能够一样,至少从服务器的MySQL版本不可以低于主服务器的数据库版本。因为MySQL不同的版本之间二进制日志可能不一样。
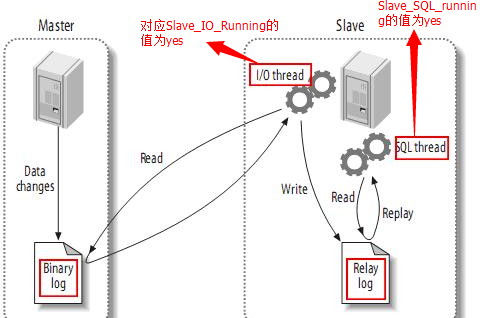
当然这种复制和重复都是MySQL自动实现的,我们只需要配置即可。
上图中有两个服务器, 演示了从一个主服务器(master) 把数据同步到从服务器(slave)的过程。
这是一个主-从复制的例子。 主-主互相复制只是把上面的例子反过来再做一遍。
2)、按备份内容:
- 日志备份:主要备份 bin-log 日志,然后 replay 来完成 point-in-time
- 完全备份:对数据库一个完整的备份
- 增量备份:在上次完全备份的基础上对更改部分进行备份(MySQL 没真正的增量备份,一般通过 bin-log 完成,要借助第三方工具才能实现)
3)、按备份文件:
- 逻辑文件:指备份出的文件可读,一般指 SQL 语句(适用库升级,迁移,但恢复时间较长需要执行 SQL 语句)
- 物理文件:指复制数据库的物理文件
其中 mysqldump 是属于逻辑备份,也是最常见的备份工具了,缺点在于备份和恢复速度不是特别快
4)、最后关于备份数据, 别忘了我们也要备份 binlog
如果有 DBA 告诉你,这个数据库能够恢复到两个个月内任何状态,这说明了,这个数据库的 binlog 日志至少保留了两个月。备份 binlog 的好处:
- 可以实现基于任意时间点的恢复
- 可以用于误操作数据闪回
- 可以用于审计
5)、关于备份恢复
a)、对于使用mysqldump进行逻辑备份的文件, mysql -u root -p [dbname] < backup.sql 进行恢复即可
b)、xtrabackup 备份全量恢复
Percona-xtrabackup是 Percona公司开发的一个用于MySQL数据库物理热备的备份工具,支持MySQL、Percona server和MariaDB,开源免费,是目前较为受欢迎的主流备份工具。xtrabackup只能备份innoDB和xtraDB两种数据引擎的表,而不能备份MyISAM数据表。
MySQL冷备、mysqldump、MySQL热拷贝都无法实现对数据库进行增量备份。在实际生产环境中增量备份是非常实用的,如果数据大于50G或100G,存储空间足够的情况下,可以每天进行完整备份,如果每天产生的数据量较大,需要定制数据备份策略。例如每周实用完整备份,周一到周六实用增量备份。而Percona-Xtrabackup就是为了实现增量备份而出现的一款主流备份工具,
xtrabackup包含两个主要的工具,即xtrabackup和innobackupex,二者区别如下:
(1)xtrabackup只能备份innodb和xtradb两种引擎的表,而不能备份myisam引擎的表;
(2)innobackupex是一个封装了xtrabackup的Perl脚本,支持同时备份innodb和myisam,但在对myisam备份时需要加一个全局的读锁。还有就是myisam不支持增量备份
Xtrabackup备份原理
Xtrabackup备份流程图(xtrabackup备份过程中,先备份innodb表,再备份非innodb表):
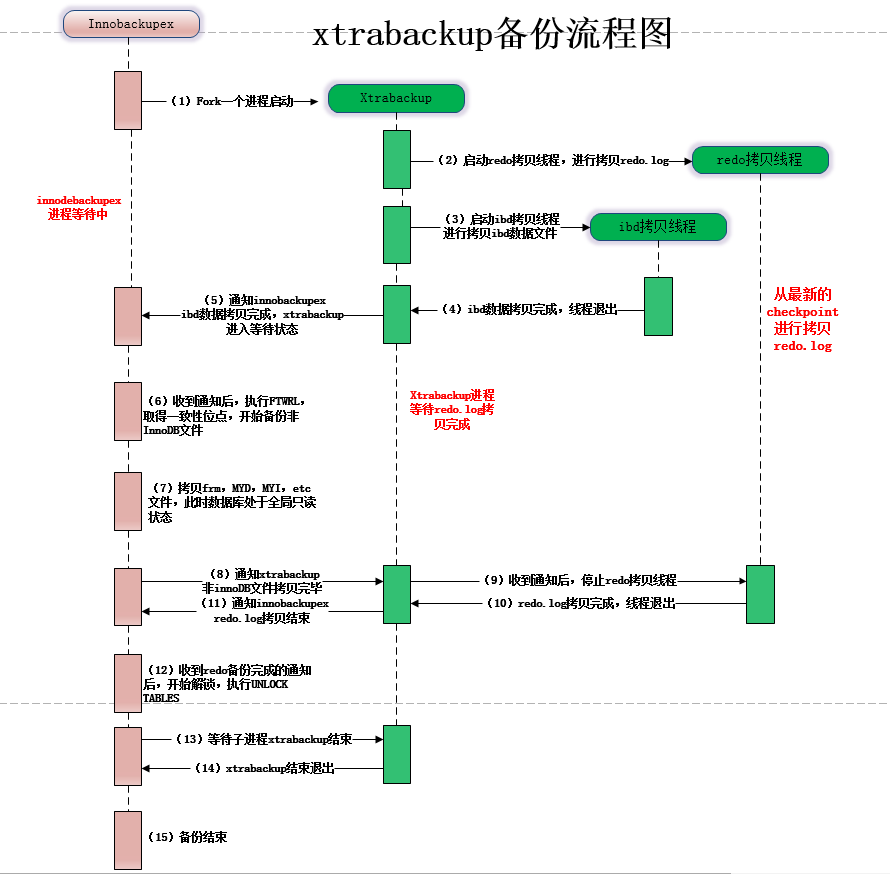
恢复过程如下:
#步骤一:解压(如果没有压缩可以忽略这一步)
innobackupex--decompress<备份文件所在目录>
#步骤二:应用日志
innobackupex--apply-log<备份文件所在目录>
#步骤三:复制备份文件到数据目录
innobackupex--datadir=<MySQL数据目录>--copy-back<备份文件所在目录>
c)、基于时间点恢复
基于时间点的恢复依赖的是 binlog 日志,需要从 binlog 中找过从备份点到恢复点的所有日志,然后应用。
show variables like 'log_bin%';
+---------------------------------+-------+
| Variable_name | Value |
+---------------------------------+-------+
| log_bin | OFF |
| log_bin_basename | |
| log_bin_index | |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
+---------------------------------+-------+
5 rows in set (0.06 sec)
查看log_bin 配置是否启用 binlog。Mysql 8.0 默认开启 binlog。
如果log_bin 是关闭, 可以修改my.conf 打开. 这里不就展开讲binlog的恢复了,想深入了解的朋友可以自己研究一下。
结语: 对于一个在正式环境运行的系统来说, 数据是最重要的了, 代码我们可以通过git来管理, 数据只能靠我们自己进行备份、只有平时做好了操作, 才能在关键时刻恢复。 比如这个经典案例, 如果平时做好了演练, 也就没有那么多事情了:

也欢迎关注我的公众号: 漫步coding, 回复: mysql免费获取最新Mysql面试题汇总(含答案)。 一起交流, 在coding的世界里漫步。

希望这篇文章可以帮助大家, 也希望大家都能找到找到的好工作。